PSA: You Can Pick Your Sub-Agent Model in Claude Code
Haiku + Sonnet hybrid that matched Opus precision at 40% of the token consumption.

With AI x Marketing, it’s such a greenfield that I’m learning and discovering new things every day.
One such thing I learnt recently: when you’re spinning up Claude sub-agents inside your Claude Code subscription (not the API), you have the ability to pick what model your sub-agents use.
This is a breakthrough for me because there were a few projects that were consuming a lot of my 5-hour limits.
Main Agent: Opus 4.7
Sub Agents: Haiku or Sonnet
The intention is that when you’re spinning up sub-agents, these sub-agents are doing non-reasoning-intensive work. Hence, you don’t need to be using the expensive reasoning model (i.e. Opus) for outputs.
Background
I ran into this issue while using Claude Code to do company research. I was trying to identify whether a company in my TAM has been actively organising webinars on their website, social media, and external channels.
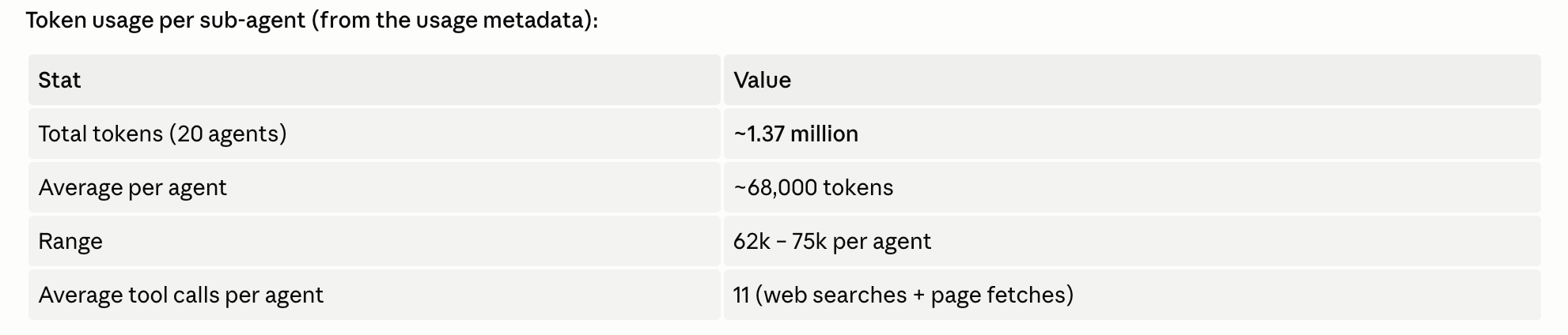
You can see that it consumed a total of 1.37 million tokens, across 20 sub-agents (1 sub-agent for 1 unique company researched).
I’m on the Max (5×) plan, so this took up 40% of my 5-hour quota.
Switch to Cheaper Models + Benchmark
Step 1: Raw token analysis, Opus vs Haiku
To understand the cost differential, I ran a 10-domain benchmark using Opus vs Haiku as the sub-agent model using the same task, same methodology.
The raw token cost was 1.37M vs 80k, a 17× reduction.
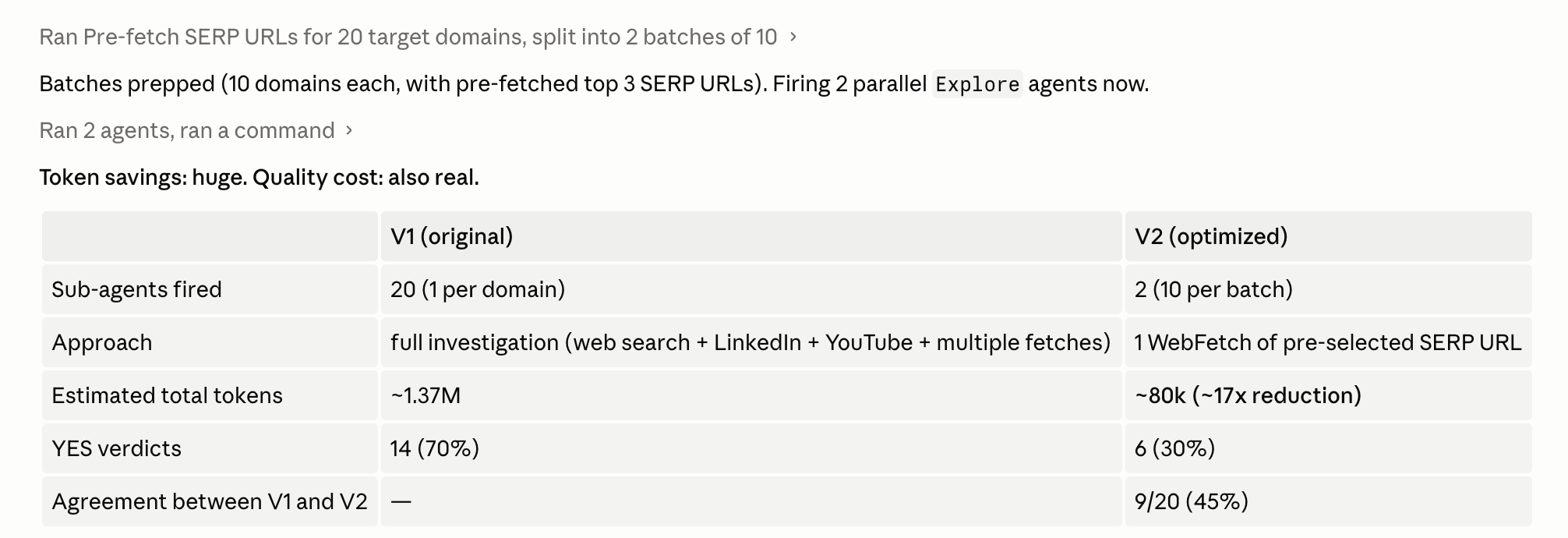
But raw tokens only tell you half the story. When I benchmarked the actual results (V1 is Opus (my control), V2 is Haiku) you can see that Haiku gave totally unusable results.

Step 2: Hybrid Approach
That’s where I realised I still needed a reasoning model somewhere in the workflow.
So I decided to use Haiku for the cheap first pass, to quickly identify any companies that matched “yes” as a parameter first. Then I escalated using Sonnet as the reasoning model to do deeper research on the results that came back as “no”.
The intention was to qualify those “no”s: are they true no’s, or are they actually yes’s that Haiku missed because it couldn’t research deeper to LinkedIn, YouTube, or partner blogs.
Pass 1: Haiku sub-agents, 1 domain per agent, full methodology (web search + 1-2 fetches + reasoning). Catches ~75-85% of YES.
Pass 2: Sonnet sub-agents on the residual, such as the UNREADABLE / NO-EVIDENCE / MAYBE results from Pass 1.
Step 3: Full benchmark with Opus vs Haiku vs Hybrid
For the proper test, I ran a 20-domain analysis on the same webinar-signal task, comparing full Opus vs full Haiku vs the hybrid (Haiku + Sonnet).
Opus is still the control.
The question I wanted to answer was: can the hybrid hit 80-90% of Opus’s results at a fraction of the cost?
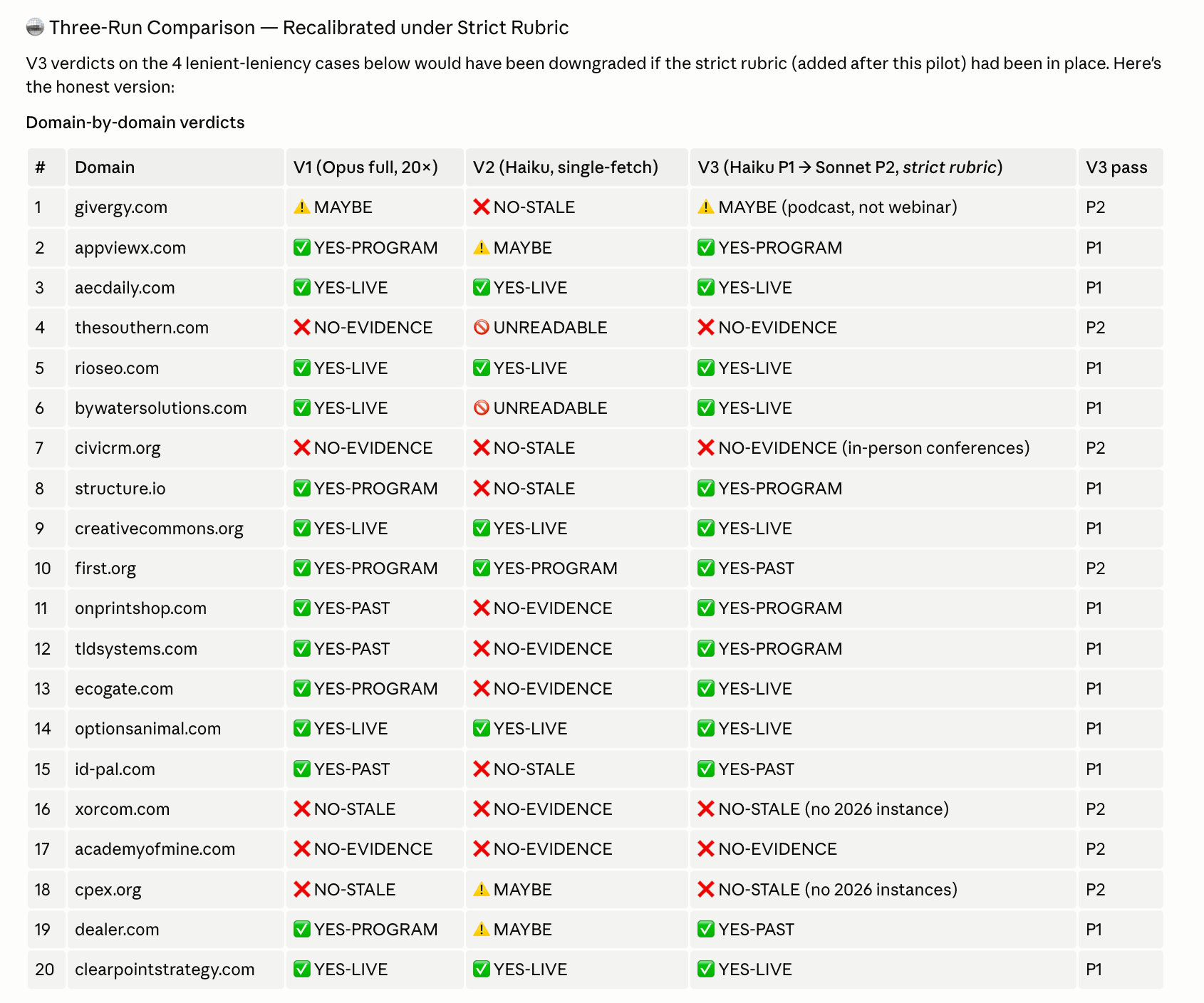
Hit rate
Opus only: 70%
Haiku only: 30%
Haiku + Sonnet: 70%
Token cost (20 domains research)
Opus only: ~1.37M
Haiku only: ~80k
Haiku + Sonnet: ~540k
You can see that V3 matches V1’s precision at ~60% lower cost.
My learnings
Two things I’m taking away from this.
Different model for different tasks.
Before spinning off sub-agents, it’s always important to have at least some idea of the complexity of the task. That’s where you can assign the proper heavier reasoning model, or the lighter reasoning model, to do the work.
Simple checks like yes/no extractions or structured lookups don’t need Opus. Anything that requires the agent to pivot, reason, or weigh ambiguous evidence is where the heavier model earns its per-token spend.
Always benchmark against your highest reasoning model as the control.
When you’re choosing different models for different parts of the work, I think it’s important to do some kind of benchmarking using Opus (or whatever your top model is) as the control.
This makes sure the quality of the output is on par with what you expect. Because sometimes if you’re just using the lower reasoning model, you get bad results, and even though you’re saving tokens, that might not serve the business objectives.
Further improvement to explore: batching
One more lever I want to flag for the next iteration is batching.
In my current setup, I fire one sub-agent per domain. Twenty domains = twenty sub-agents. Each sub-agent starts fresh: it loads its instructions, its tool list, and its task description before doing any real work.
I’ll call this the warm-up cost and for a Claude Code sub-agent, it’s around 25-35k tokens before the agent has done anything useful.
Batching means giving one sub-agent multiple jobs in a single run. Instead of 20 sub-agents each warming up separately, you fire 2 sub-agents that each handle 10 domains. You pay the warm-up cost twice instead of twenty times.
I actually tried this earlier in the project (V2 in my comparison table). Two sub-agents, ten domains each. Total token cost dropped from 1.37M to 200k, a 7× reduction.
But there’s a real trade-off, and it comes down to attention budget. Each sub-agent only has so much attention to spread across its work. When that attention has to cover ten domains in one run, the agent can’t pivot to LinkedIn, YouTube, or partner blogs when the first fetch comes up empty. Recall dropped from 70% to 30%. I was saving tokens, but missing half of the real prospects.
So batching isn’t free. It saves on warm-up cost but constrains how deep the agent can investigate any one item.