Inside Andrew Ng’s Agentic AI Course: 15 Learnings on Building Agentic Workflows
Reflection, tool use, planning, and multi-agent workflows.

I took Andrew Ng’s Agentic AI course (DeepLearning.AI).
Verdict: 9.5/10. Highly recommend.
It covers the fundamentals of agentic workflows, which includes: reflection, tool use, planning, and multi-agent systems.
It also provides solid theories and examples on evaluation, optimization, and error analysis, something that I think areas most people (including me) skip when building their first AI systems.
Just wanted to share 14 key learnings from the course that I found most useful.
#1: Agentic Workflow Development Process Summary
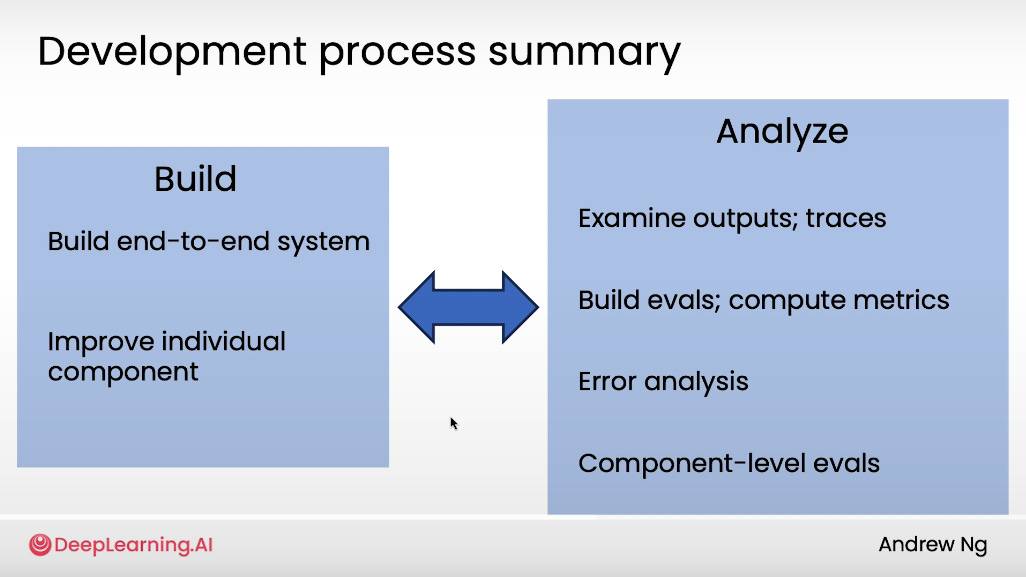
Your agentic workflow development has two “modes” — Build and Analyze — and you should move constantly between them.
Build: Start fast. Get an end-to-end system running (even rough). Then improve components as signals appear.
Analyze: Examine outputs, read traces, and run small evals (10–20 samples). Track metrics, do error analysis, and isolate weak components.
Then cycle between both.
You start by building a quick, end-to-end system
Then you analyze right away by look at outputs, read traces, spot underperforming components.
That analysis informs what to fix next.
You repeat this loop: build → analyze → build → analyze, tightening it each round.
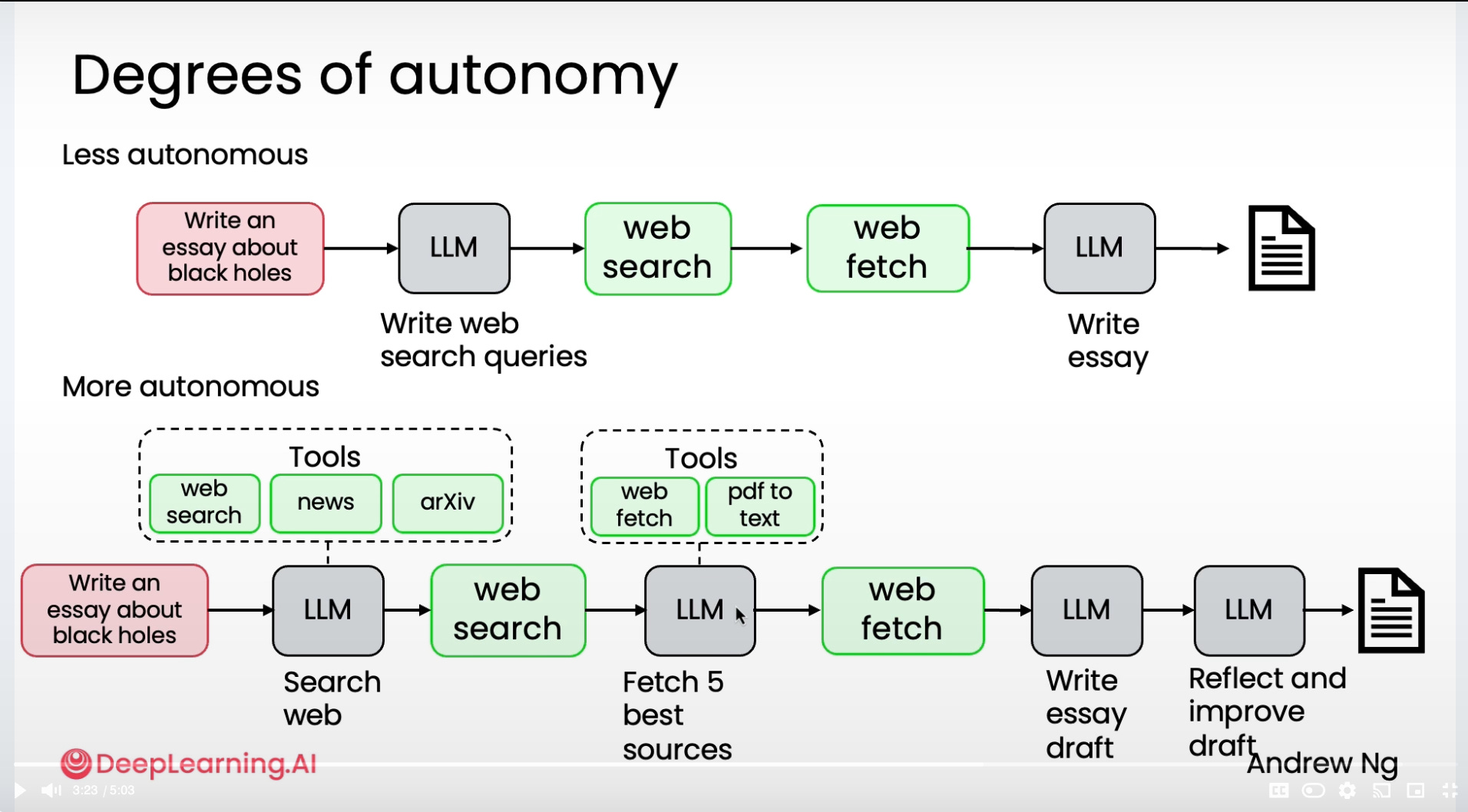
#2: Degrees of Autonomy
I thought this was one of the more interesting sections for me personally.
There’s always debate (especially on Linkedin) on what counts as an “agentic” workflow.
Most people see it as binary, meaning a workflow is either agentic, or it isnt.

Andrew defines it differently. An agentic AI workflow is simply when an LLM-based app executes multiple steps to complete a task.
And instead of a yes/no definition, he frames it as a spectrum of autonomy:
Less autonomous: fixed, hard-coded steps.
More autonomous: the LLM decides which tools or actions to take
#3: Parallelism for Speed
Always consider parallelism workflows for speed.
It gives you:
Better performance
Faster than humans
Modularity as you can swap tools, models, or components anytime
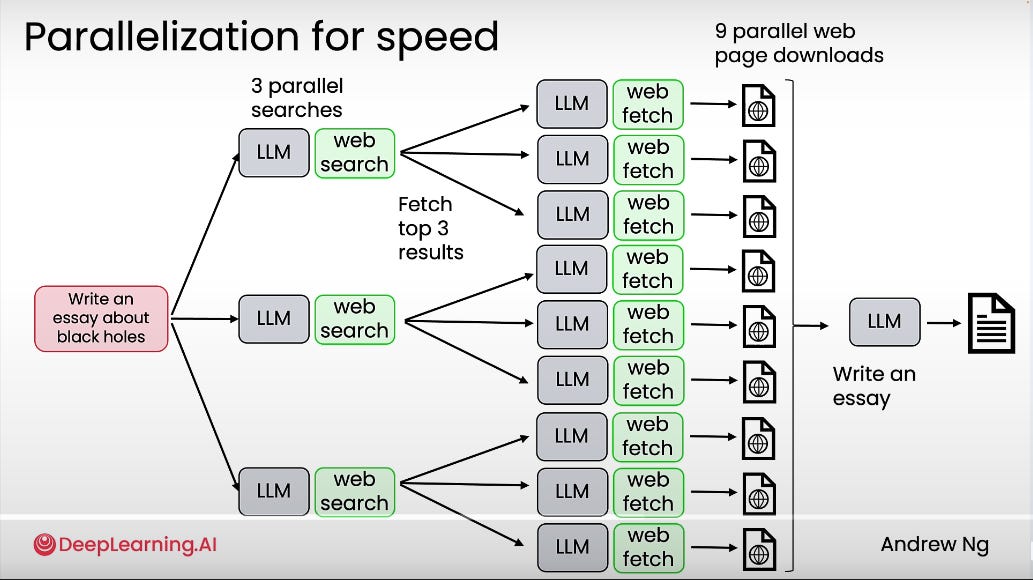
In the example above, instead of fetching pages one by one, the system can parallelize all nine web downloads, then feed them into the LLM to write the essay.
#4: Agentic Workflow Evaluations


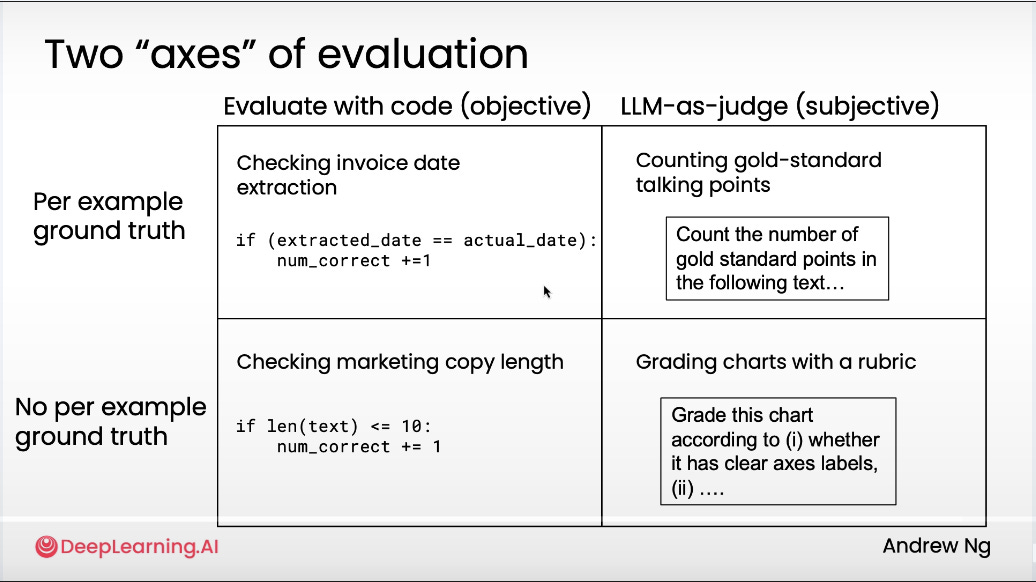
Agentic workflow evaluations help you troubleshoot why a workflow isn’t performing and pinpoint exactly where it’s breaking down.
Here’s an eval framework:
Define what “good” looks like.
Before running evals, know what success means, IE what specific output or behavior you’re expecting from the workflow.Start small.
Run a mini-eval on 20–50 examples.
This gives you fast signal on which step or component needs improvement.Pick the right eval type:
Objective: measurable accuracy (e.g., output Y = expected Y).
Subjective: LLM or human-judged quality (e.g., clarity, tone, reasoning).
#5: Objective vs Subjective Evaluations
Objective evals are for tasks with clear right or wrong answers.
They’re code-based, grounded in hard truths, and measured against known results.
Use code-based evals when outputs can be verified automatically
Build a dataset of ground-truth examples to test agains

Subjective evals use an LLM as a judge when there’s no single “correct” answer.
Example are for tasks like reasoning, tone, or visual clarity.
Key insight: Grading with a rubric framework gives more consistent, repeatable results.
Example rubric for chart evaluation:
Has a clear title
Axis labels are present
Chart type is appropriate
Axes use the correct numerical range
Each rule gets a binary score (1 or 0), then aggregated. The LLM grades performance objectively within a subjective task, thus keeping feedback structured instead of fuzzy.

#6: End to End vs Component Eval
End-to-end evals are expensive! You have to run the entire workflow just to see what needs improvements.
Component-level evals are more surgical. You can isolate which part of the workflow is not up to expectations, so you know exactly where to focus improvements.
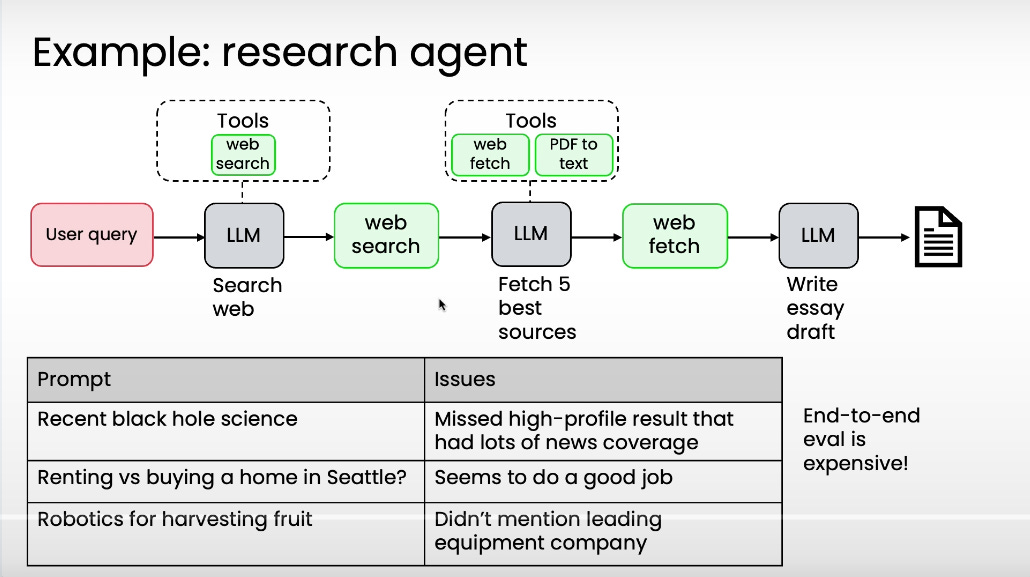
Use end-to-end evals to test the full user experience.
Use component evals to debug faster and save compute.
#7: Reflection to Improve Outputs
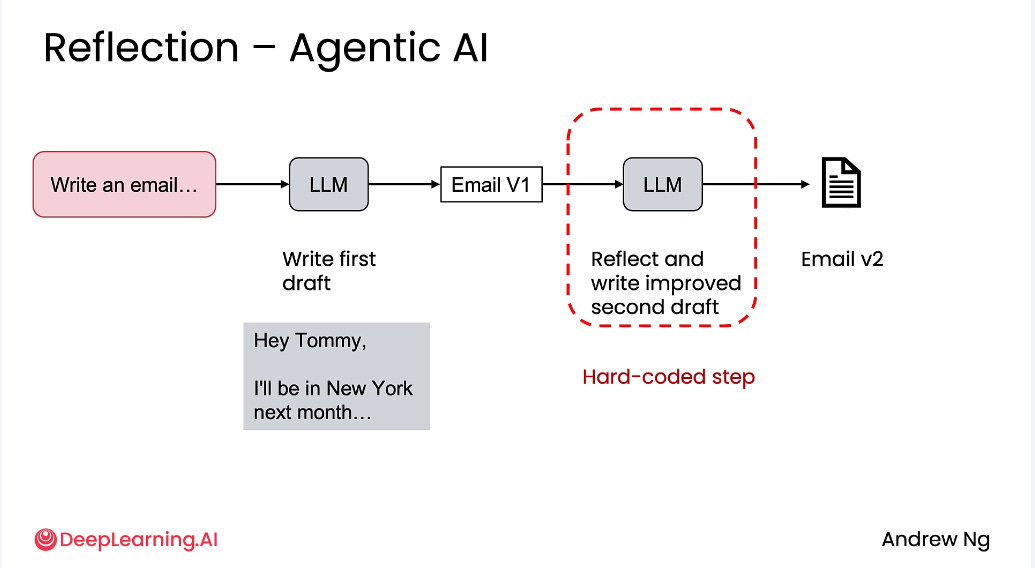
I must admit… this portion on “reflection” is interesting.
I never thought of putting in a “reflection” step to improve on outputs, but it make so much sense.
The idea is very simple: after the LLM writes the first draft, it reviews its own output, identifies weaknesses, and rewrites a better version.
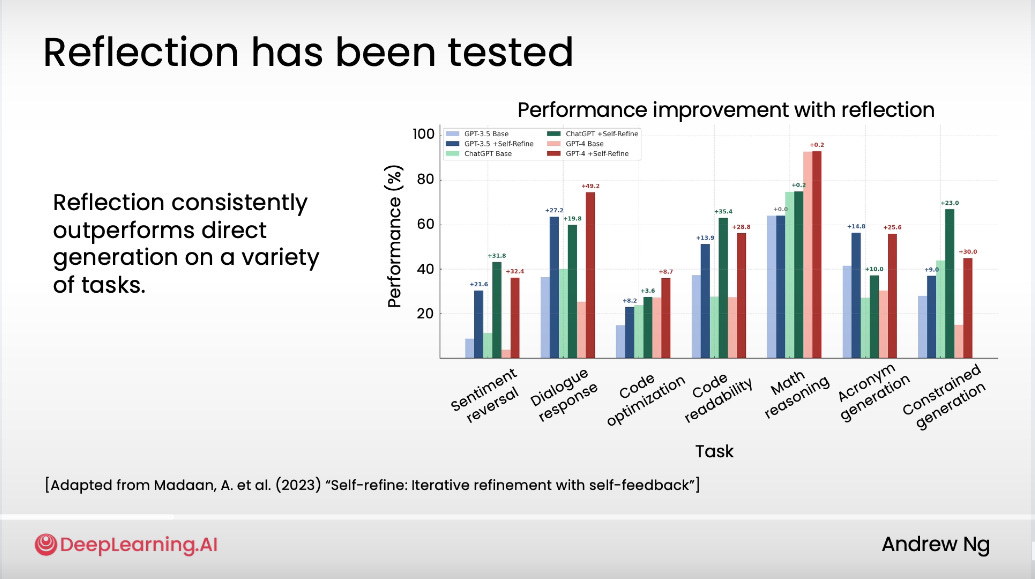
Why? Because reflection = increased performance
How to do reflection:
Explicitly define what “reflection” means in that context. IE tell the LLM what to reflect on (e.g., factual accuracy or reasoning gaps) and what to check (clarity, logic, tone, etc.)
Don’t use “fuzzy” reflection logic such as “improve this” or “make it better”
#8: Reflection (with feedbacks)
Reflection can also come externally.
You can connect external tools that the LLM can call for feedback. Then feed those feedback signals back into the model to refine its next output.

Note → Reflection gets stronger when you combine LLM self-critique + external feedback loops.
#9: LLM Tools
LLMs can be equipped with tools (functions) to take action or retrieve data.
Instead of hardcoding every step, you let the LLM decide when to call a tool.
This is an important first step in building more autonomous agentic workflows, giving the LLM autonomy to plan and execute actions on its own.
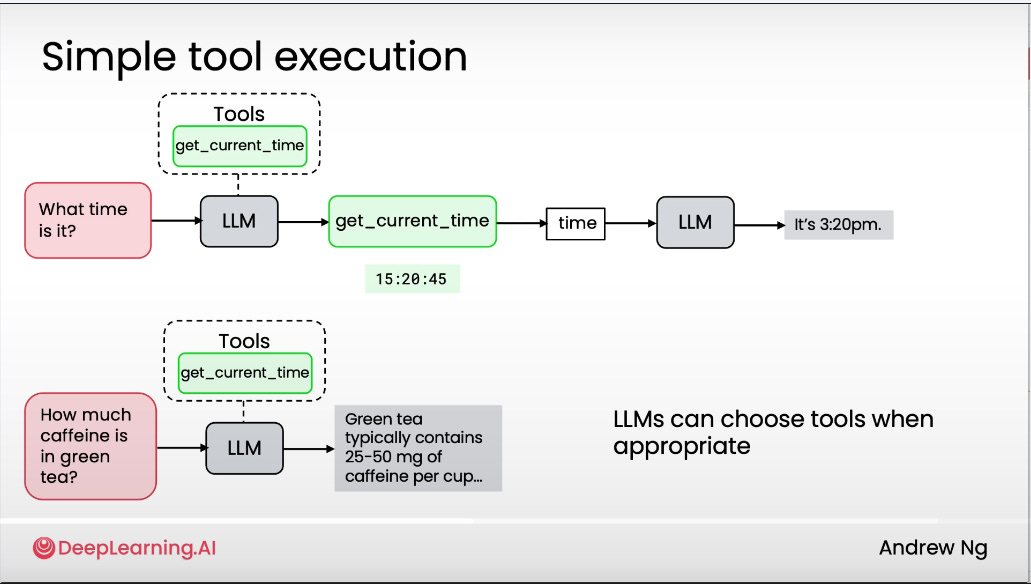
#10: Error Analysis
Two key takeaways from this section.
1. Analyze errors on a component level
Break your workflow down and check which step is producing outputs that don’t match your expectations.
2. Measure manually
Compare each component’s output to what you expect it to produce and track which step underperforms most often.

Without proper error analysis, you waste time tweaking things randomly. Instead of fixing the component that actually bottlenecks your workflow performance.

Andrew shares four ways to improve LLM component performance:
Improve your prompts
Try a new model
Split up the step
Fine-tune a model
Personally, I’ve found little uplift from switching models. Think that today, most are “good enough” for typical use.
But improving prompts and splitting steps into smaller parts has delivered noticeable performance gains for my workflows.
#11: Latency & Cost Optimization
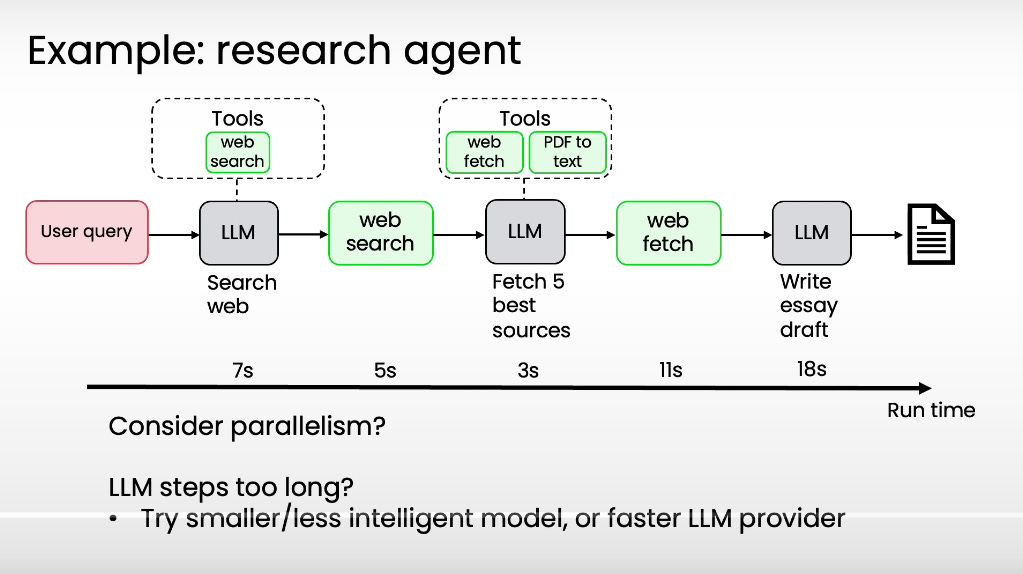
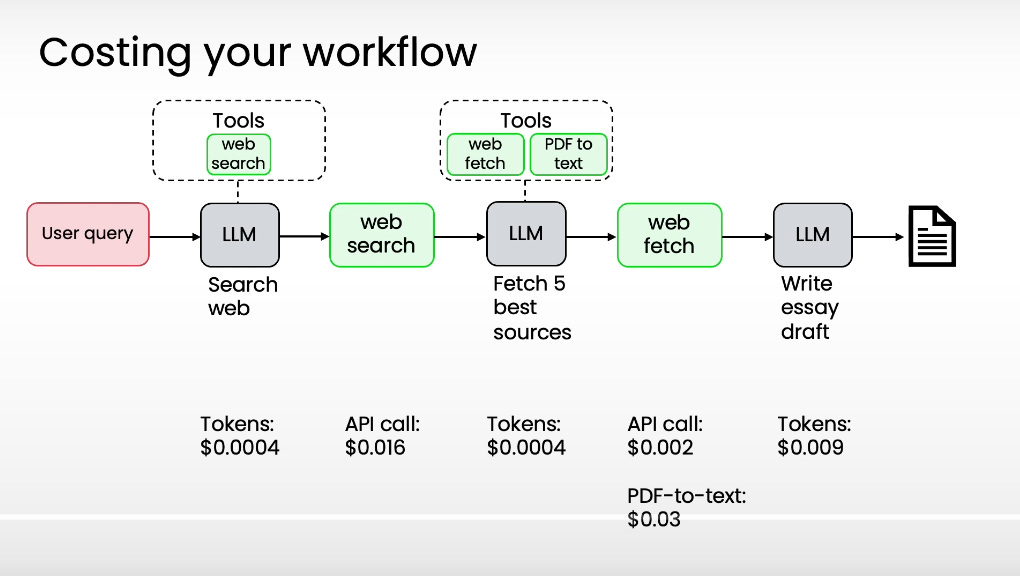
Both latency and cost matter… but in practice, latency usually matters more.
Token costs are often negligible, while slow responses hurt user experience and cap your workflow’s runtime.
I would say that generally only optimize cost when it’s significant, but focus first on making your workflow feel fast.
#12: [Pro Tip] Real Automation = The LLM Plans, You Don’t
This section was a real eye-opener for me.
When building agentic workflows, you can and should ask the LLM to plan the steps first. Let it figure out how to solve the problem before it starts executing.
I’d been doing it backwards. Hardcoding every step instead of letting the model design the plan itself.
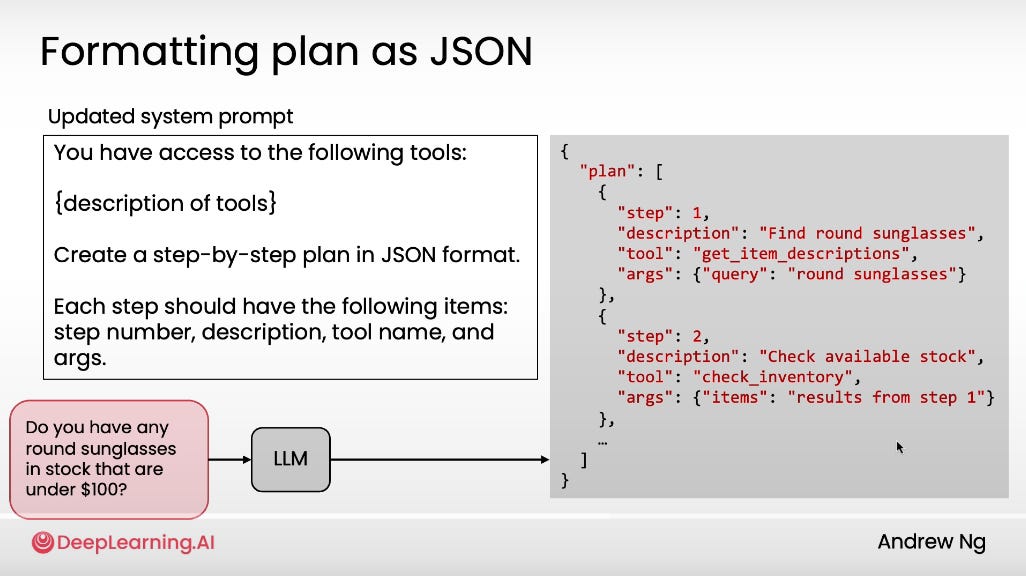
Although, I think the sweet spot might be a mix of full autonomy and semi-autonomy.
Have the LLM to plan out the steps first
Hard code the steps
Run 50 times to do proper error analysis and component analysis
Because if the steps aren’t discrete, it’s hard to measure where things go wrong or which part underperforms. Food for thought.
#13: [Pro Tip] Shortcut Workflow’s Edge Cases Through External Libraries
To handle your workflow’s edge cases, you can make use of existing libraries.
Instead of create a standalone tool for each edge case (time consuming, not practical).
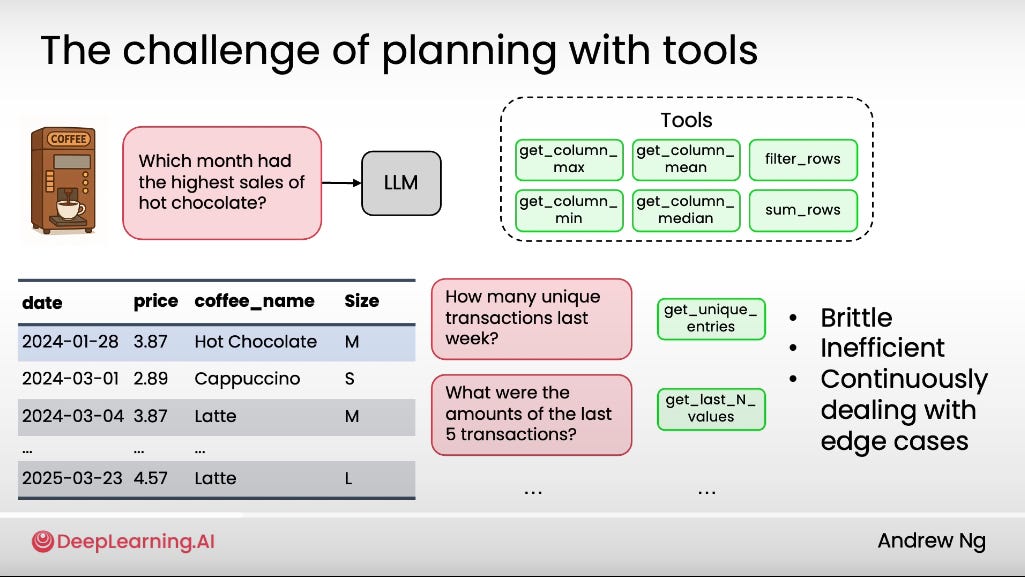
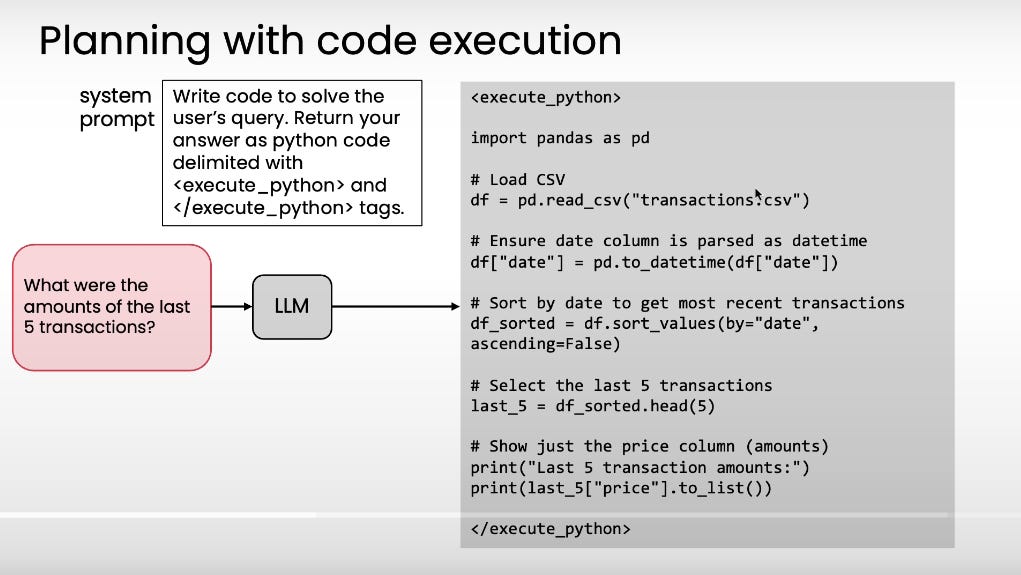
Take Pandas library in Python for example. it has hundreds (even thousands) of functions for data processing.
By letting the LLM write code and call those functions, it can string together multiple operations to solve complex queries on its own.
#14: Multi-Agentic Workflow
Think of agents like specialized tools the LLM can call when needed.
Instead of one big linear workflow, the LLM plans and coordinates across multiple roles.
Creating different agents (similar to tools) that the LLM can call
Ask the LLM to carry out the plan
Execute
The workflow becomes non-linear
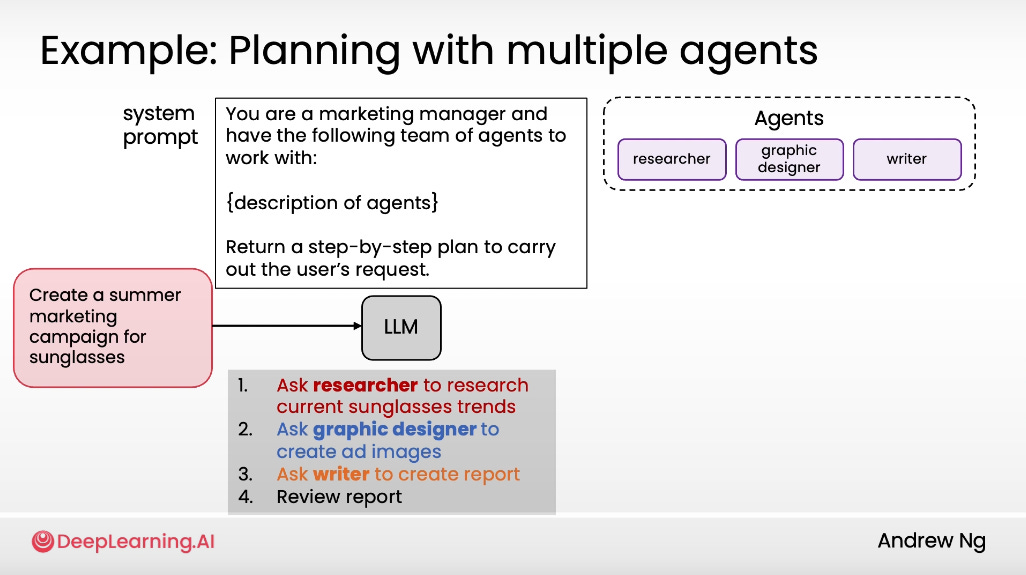
Wrap Up: Strong Fundamentals Win
I really enjoyed this course.
It covers the core fundamentals of agentic workflow design, something rarely explained this clearly anywhere else.
Highly recommended for anyone that is starting out in agentic workflow building.
I test AI workflows on real marketing problems.
And turn the useful ones into 10x Playbooks.
So business owners and solo marketers doing it all themselves can skip the guesswork… and copy what actually works.
→ I drop one of these 10xPlaybooks 🚀 every week. Don’t miss the next.
John
Hey, great read as always, your point about the iterative build-analyze loop and the absolutly critical role of consistent evaluation and error analysis is so insightful and often overlooked, truly foundational for building robust agentic systems.